Chapter 5 Limpieza de datos
A continuación, voy a hacer la limpieza de las muestras poco informativas. Observa en la siguiente gráfica la distribución de las muestras.
# Guardar nuestro objeto RSE por si luego cambio de opinión
rse_gene_unfiltered <- rse_gene
# Restablecer el objeto RSE a una instancia antes del filtrado
#rse_gene <- rse_gene_unfiltered
# Graficar la distribucion de las muestras
hist(rse_gene$assigned_gene_prop)
abline(v=0.37,col = "red")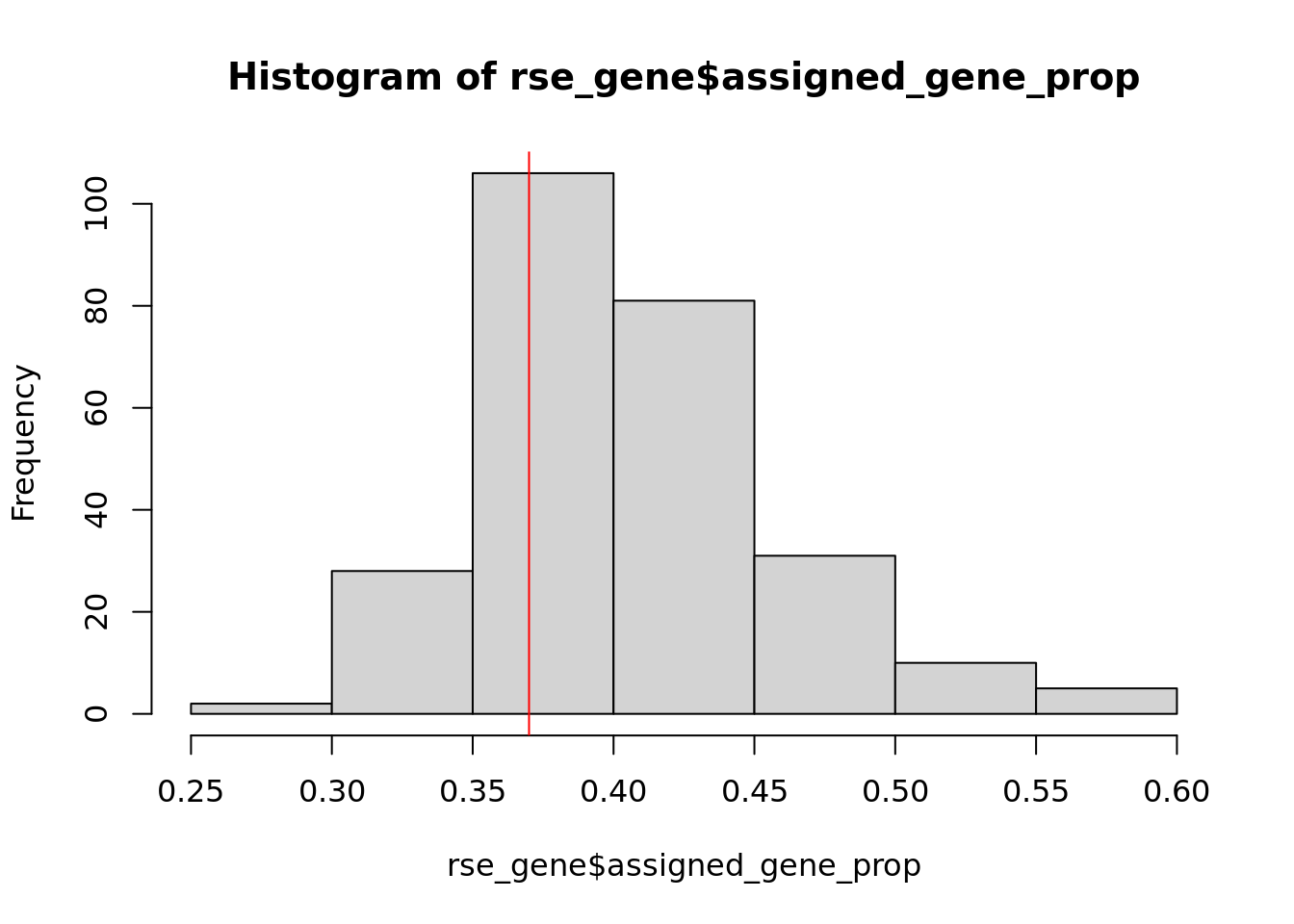
Se descartan las uestras que estan por debajo de un umbral de 0.37, el cual representa el primer cuartil. La distribución resultante es la siguiente.
# Eliminar las muestras de menor calidad
rse_gene <- rse_gene[, rse_gene$assigned_gene_prop > 0.37]
hist(rse_gene$assigned_gene_prop)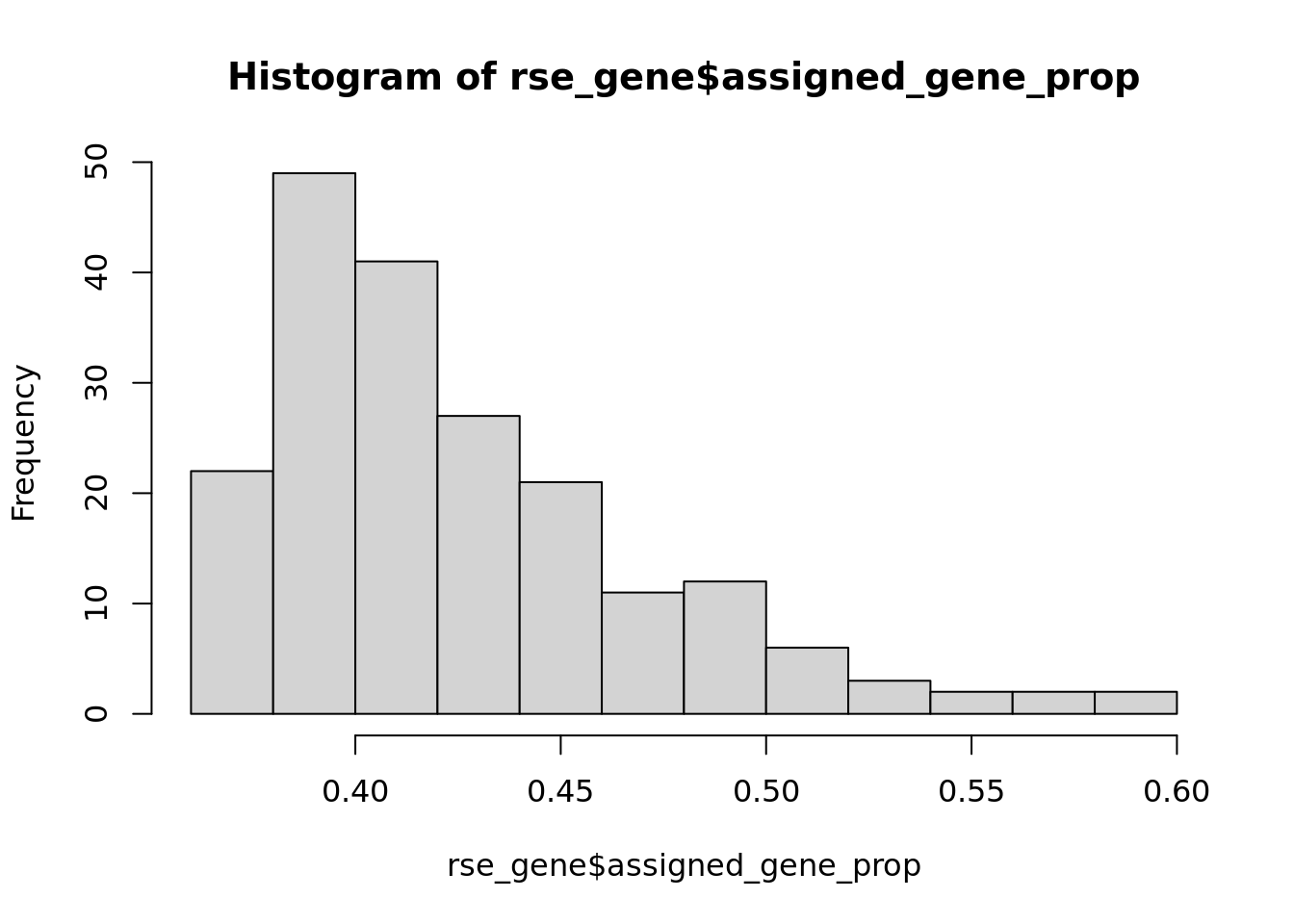
Es momento de hacer limpieza de genes poco informativos. Las estadísticas de todos los genes son las siguientes.
# Obtener estadísticas de la expresión de genes
gene_means <- rowMeans(assay(rse_gene, "counts"))
summary(gene_means)## Min. 1st Qu. Median Mean 3rd Qu. Max.
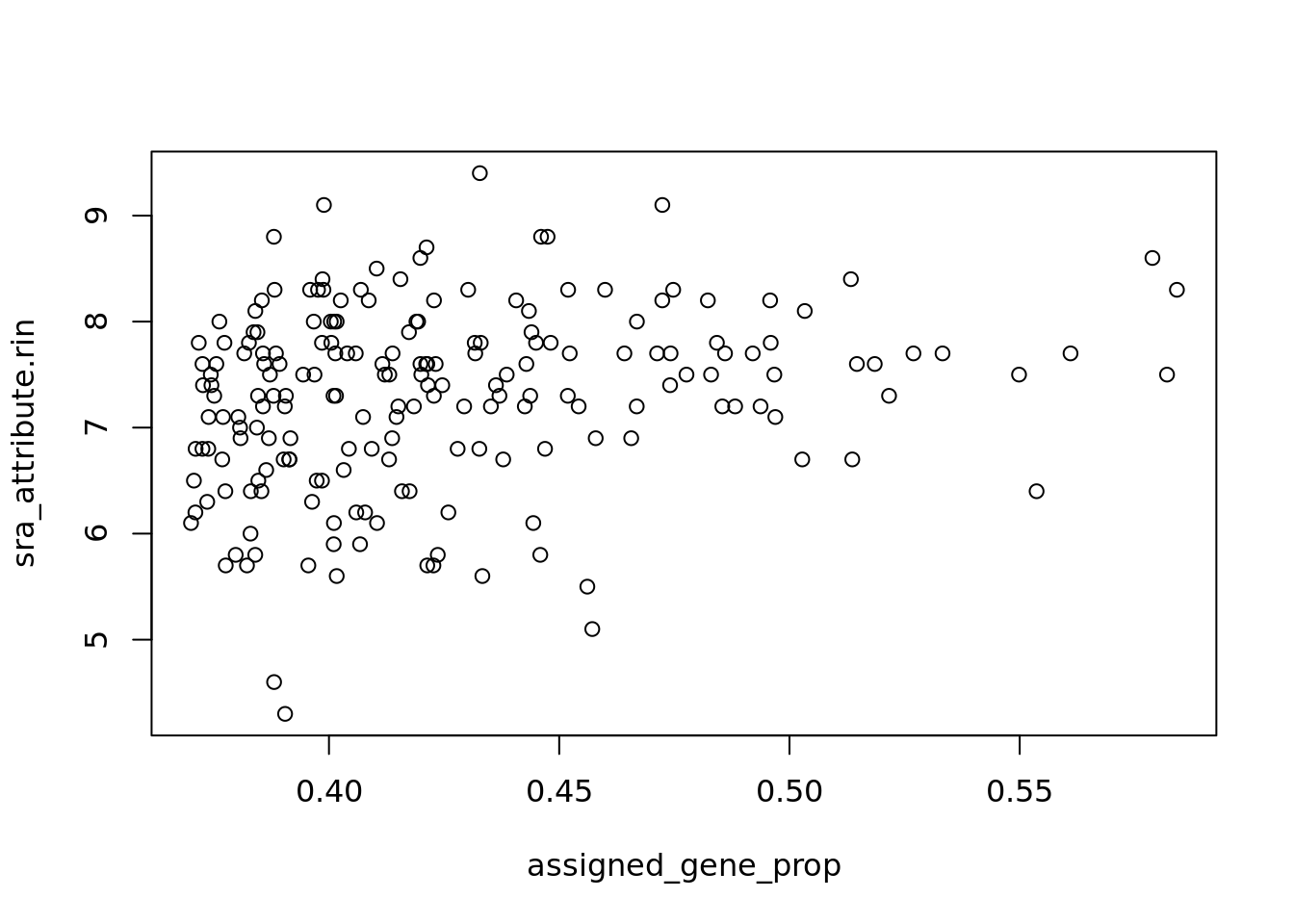
## 0.0 0.2 3.5 403.3 74.5 888097.9Se eliminará de nuevo el primer cuartil. Por último, se índica el porcentaje de muestras conservadas depués del filtrado. En este caso, me quede con aproximadamente el 73.4% de los datos originales. De nuevo muestro la gráfica RIN, pero esta vez con los datos filtrados. Al parecer, la calidad de los datos mejoró considerablemente después de la limpieza.
# Filtrar genes
rse_gene <- rse_gene[gene_means > 0.2, ]
round(nrow(rse_gene) / nrow(rse_gene_unfiltered) * 100, 2)## [1] 73.39# Graficar los niveles de expresion RIN
with(colData(rse_gene), plot(assigned_gene_prop, sra_attribute.rin))